
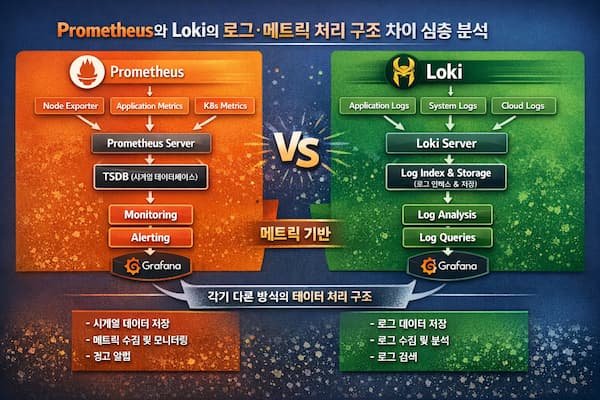
관측(Observability) 스택을 설계할 때 가장 많이 같이 언급되는 조합이 Prometheus와 Loki에요. 둘 다 Grafana 생태계에서 자주 함께 쓰이지만, 내부 구조와 “무엇을 저장하고 어떻게 질의하는지”는 완전히 달라요.
Prometheus는 메트릭 중심, Loki는 로그 중심이라는 단순 구분을 넘어, 수집 방식, 저장 포맷, 인덱싱 전략, 쿼리 실행 모델까지 설계 철학이 다르기 때문에 운영 비용과 성능 특성이 크게 달라져요.
이번 글에서는 Prometheus와 Loki를 구조 관점에서 깊게 비교해, 어떤 상황에 무엇을 선택하고 어떻게 조합하는 게 좋은지까지 정리해볼게요.
1. 메트릭과 로그의 “데이터 모델”이 근본적으로 다르다
메트릭은 “시간에 따른 숫자”에요. CPU 사용률, 요청 수, 지연 시간 같은 값이 일정 주기로 기록되죠. 그래서 Prometheus는 기본적으로 시계열 데이터베이스(TSDB) 구조를 전제로 설계돼요.
로그는 “이벤트의 연속”이에요. 같은 1초 안에도 수천 줄이 찍힐 수 있고, 각 줄이 비정형 텍스트이거나 JSON일 수도 있어요. 그래서 Loki는 로그 라인을 대량으로 저장하고, 필요할 때 라인을 필터링하거나 파싱하는 방향으로 설계돼요.
정리하면 데이터의 성격이 달라서, 저장 최적화와 인덱싱 방식이 처음부터 달라질 수밖에 없어요.
2. 수집 방식의 차이: Pull 기반 Prometheus vs Push 친화 Loki
Prometheus의 기본 수집은 Pull 방식이에요. Prometheus 서버가 주기적으로 대상 엔드포인트(/metrics)를 긁어와요. 이 구조의 장점은 “수집 기준이 중앙에 있다”는 점이에요. 스크레이프 주기, 타임아웃, 레이블 정책을 중앙에서 통제하기 좋아요.
Loki는 보통 Promtail, Fluent Bit, Grafana Agent 같은 수집기를 통해 Push 형태로 들어와요. 로그는 대상이 “지속적으로 뿜는 스트림”이라 Pull이 비효율적이기 때문이에요. 결국 Loki는 로그 스트림을 받아서 청크로 묶고 압축해 저장하는 쪽으로 최적화돼요.
실무에서의 차이는 이거예요.
Prometheus는 “대상이 살아있고 /metrics를 노출하면” 수집이 쉽고, Loki는 “노드/파드가 찍는 로그를 끌어모으는 파이프라인”을 먼저 잘 만들어야 해요.
3. 저장 구조 차이: TSDB 블록 vs 로그 청크(Chunk)
Prometheus는 TSDB를 사용해요. 일정 시간 단위로 블록을 만들고, 블록 안에 여러 시계열 샘플을 효율적으로 압축해서 저장해요. 핵심은 “레이블 집합이 같은 시계열”에 대해 시간축으로 매우 빠르게 조회할 수 있게 하는 거예요.
Loki는 로그 라인을 “스트림(stream)” 단위로 묶고, 스트림별로 청크를 만들어요. 청크는 일정 크기나 시간 기준으로 닫히고 압축돼요. Loki의 핵심은 “로그 본문 전체를 광범위하게 인덱싱하지 않고도” 저장 비용을 낮추는 거예요.
결과적으로 Prometheus는 숫자 샘플의 시계열 압축에 강하고, Loki는 텍스트 로그를 대량으로 저장하는 비용 효율에 강해요.
4. 인덱싱 전략 차이: Prometheus는 시계열 인덱스, Loki는 라벨 인덱스 최소화
Prometheus는 기본적으로 모든 시계열이 레이블 셋으로 식별돼요. 레이블이 사실상 인덱스 키 역할을 하며, 쿼리는 “어떤 레이블을 가진 시계열”을 뽑고 그 위에서 집계/연산을 해요. 그래서 레이블 설계가 곧 성능 설계예요.
Loki는 “로그 본문을 인덱싱하지 않는다”가 핵심 철학이에요. Loki가 인덱싱하는 건 보통 라벨(예: app, namespace, pod, host) 같은 메타데이터 정도고, 실제 로그 내용 검색은 청크를 읽어오고 나서 필터링하는 방식이에요.
이 차이가 굉장히 중요해요.
Prometheus는 “레이블 차원이 늘어나면” 시계열 수가 폭발하고 비용이 급증해요(카디널리티 문제).
Loki는 “로그 본문을 인덱싱하지 않기 때문에” 무작정 텍스트 전체 검색을 자주 하면 쿼리 비용이 급증해요(청크 스캔 비용).
5. 쿼리 엔진 차이: PromQL의 수학적 집계 vs LogQL의 필터링 중심
Prometheus는 PromQL이라는 시계열 연산 언어를 써요. rate, sum, histogram_quantile 같은 함수로 “숫자 데이터”를 통계적으로 처리하는 데 최적화돼 있어요. 목표는 대시보드와 알람에 바로 쓰기 좋은 집계 결과를 빠르게 만드는 거예요.
Loki는 LogQL을 써요. LogQL은 크게 두 축이에요.
첫째, 로그 라인을 라벨로 좁히고 필터로 걸러서 텍스트를 찾는 것
둘째, 로그에서 수치(예: duration, status)를 추출해 메트릭처럼 집계하는 것
여기서 중요한 현실은 이거예요.
Prometheus는 메트릭 집계가 “원래 목적”이라 쿼리 효율이 안정적이고,
Loki는 로그에서 메트릭을 뽑을 수 있지만, 그건 어디까지나 “로그 기반 파생”이라 쿼리 전략을 잘못 잡으면 비용이 크게 늘 수 있어요.
6. 확장성(Scale) 모델: Prometheus는 샤딩이 어렵고, Loki는 분산을 전제로 설계되는 편
Prometheus 단일 서버는 강력하지만, 초대형 규모로 가면 수평 확장이 까다로운 편이에요. 보통은 페더레이션, 샤딩, 리모트 라이트(Thanos/Mimir 등)로 확장해요. 즉, Prometheus 자체만으로 무한 확장이라기보다 “주변 컴포넌트와 함께 확장”하는 구조가 흔해요.
Loki는 비교적 분산형 아키텍처를 염두에 둔 구조가 많아요. 인제스터가 청크를 만들고, 스토리지(오브젝트 스토어)에 저장하고, 쿼리어가 필요한 청크를 읽어오고, 인덱스 게이트웨이가 라벨 인덱스를 제공하는 식으로 역할이 나뉘어요. 로그는 대량 유입이 당연하니, 수평 확장 가능성을 먼저 고려하는 방향이에요.
7. 운영 비용과 병목 포인트가 서로 다르다
Prometheus의 비용 폭탄 포인트는 보통 카디널리티에요.
레이블에 user_id, request_id 같은 고유값을 넣으면 시계열 수가 기하급수적으로 늘어나고, 메모리와 스토리지가 급격히 소모돼요. 그래서 Prometheus는 “레이블 절제”가 안정성의 핵심이에요.
Loki의 비용 폭탄 포인트는 로그 볼륨과 쿼리 패턴이에요.
라벨을 너무 세분화하면 인덱스가 커지고, 라벨을 너무 대충 잡으면 쿼리에서 너무 많은 청크를 읽어 스캔 비용이 커져요. 그리고 “본문 전체를 자주 검색”하는 사용 패턴이 많으면 쿼리가 비싸져요. Loki는 “라벨 설계 + 로그 샘플링/필터링 + 쿼리 습관”이 비용을 결정해요.
8. 언제 Prometheus가 유리하고, 언제 Loki가 유리한가
Prometheus가 유리한 경우
서비스 SLO/SLA 지표, 알람, 대시보드를 숫자로 안정적으로 운영해야 할 때
지연 시간, 에러율, QPS 같은 지표를 집계/비교/예측해야 할 때
카디널리티를 통제할 수 있는 메트릭 설계를 할 수 있을 때
Loki가 유리한 경우
장애 조사 시 “그 시각에 무슨 이벤트가 있었는지” 로그 라인을 빠르게 따라가야 할 때
분산 환경에서 파드/노드가 자주 바뀌고, 로그를 중앙에 모아야 할 때
본문 인덱싱 비용을 감당하기 어려워 “메타 라벨 인덱스 + 청크 스캔” 모델이 더 합리적일 때
9. 가장 현실적인 결론: 둘은 경쟁이 아니라 역할 분담이다
운영 관점에서 가장 좋은 패턴은 보통 이 조합이에요.
Prometheus는 알람과 대시보드의 기준선을 만든다.
Loki는 알람이 울렸을 때 원인을 파고드는 증거를 제공한다.
예를 들어 Prometheus 알람에서 “5xx 비율 상승”을 감지하면, Loki로 같은 시간대의 해당 서비스 로그를 라벨로 좁혀 에러 스택이나 특정 엔드포인트 문제를 찾는 방식이에요. 이 흐름이 가장 빠르고 비용도 예측 가능해요.
10. 정리 및 결론
Prometheus와 Loki는 둘 다 관측 스택에서 중요하지만, 내부 구조 철학이 달라요.
Prometheus는 시계열 메트릭을 빠르게 집계하고 알람을 만드는 데 최적화된 TSDB 중심 구조이고, Loki는 로그 본문을 과도하게 인덱싱하지 않고 청크 기반으로 저장해 비용 효율을 확보하는 로그 중심 구조에요.
핵심 요약은 이거예요.
Prometheus는 레이블 카디널리티가 성능과 비용을 지배하고
Loki는 라벨 설계와 쿼리 스캔 범위가 성능과 비용을 지배해요.